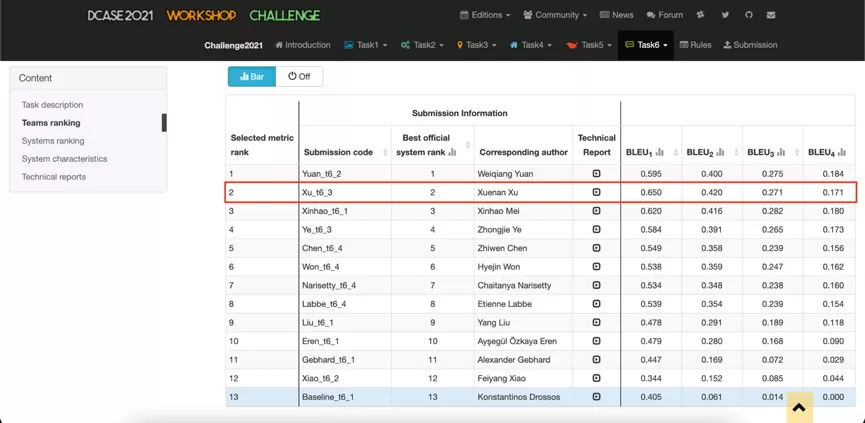
近期,上海交通大学X-LANCE实验室参加2021年丰富音频领域旗舰挑战赛DCASE (Detection and Classification of Audio Scenes and Events) 自动音频摘要任务,采用音频事件分类任务预训练编码器和强化学习方法,超越了卡内基梅隆大学、中国科学院大学、字节跳动等国内外著名研究机构及高校提出的模型,在比赛中获得了总体第二名,高校第一名的结果。
比赛简介 及 任务定义
丰富音频研究近年来逐渐成为音频研究的热点,包括声音场景分类、声音事件检测等语音之外的音频内容研究。DCASE挑战赛是一年一度的声学场景和声音事件检测与分类比赛,自2016年起已经连续举办六届,其包含的任务类型也逐渐丰富,吸引了越来越多的国际著名研究团队参与,极大推动了声音场景和音频事件检测的相关研究进步。
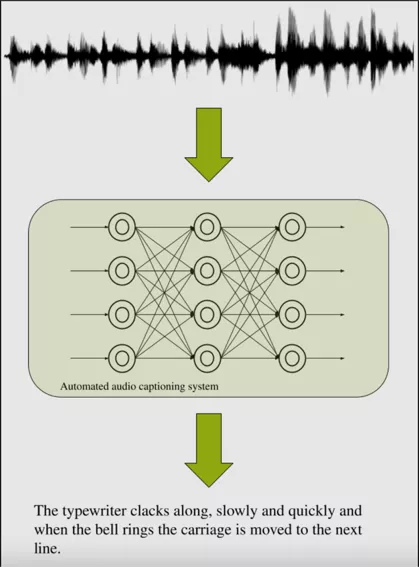
图1. 自动音频摘要任务
本次X-LANCE 实验室参加的自动音频摘要任务自2020年开始,主要目标即自动生成不受约束的自然语言描述丰富音频的内容。丰富音频指音频的内容没有限制,不一定要包含语音或者某类声音,不局限在某个场景。音频摘要的内容可能包括:1. 声音的性质;如,低沉的声音2. 环境;如,人们在小而空的房间里谈话3. 高层次的、抽象的知识;如,钟敲了三次。这一项任务将既往音频内容的单纯分类推向了更加类人的理解层面,要求用自然语言描述复杂、有关联的多项事件。
比赛数据
本次比赛的官方数据集是Clotho,分成development, validation, evaluation三个公开的子集和一个不公开的test子集,参赛队伍在公开部分的数据上训练和验证模型效果,最终排名由模型在test集合上的性能决定。Development, validation和evaluation集合共包含约6000个时长为15~30秒的音频片段,每条音频对应五个不同的人工标注。由于数据集较小,选择合适的额外数据、预训练模型成为本任务的重点。本次比赛也鼓励使用官方数据集之外的额外数据及预训练模型。
挑战与方法
由于音频摘要任务相比声音场景和声音事件检测任务,标注形式为自然语言,标注过程较为麻烦,所以该任务的数据集大小非常有限,标注较为多样,同一条音频可能对应着多个不同风格的摘要,描述上使用的词语、句式有一定差异,给模型的训练带来一定的挑战。
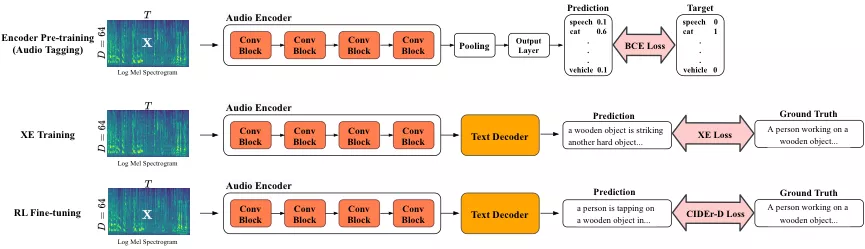
图2. 基于预训练和强化学习的音频摘要模型概览
我们本次任务采用的是encoder-decoder结构,encoder从输入音频中提取压缩过的、有用的信息,通常是一个embedding序列,decoder将这个embedding序列解码成具体的描述。由于音频摘要的重点描述内容通常是声音事件,我们选择AudioSet这个大规模的声音事件数据集做预训练。Decoder采用的是单层的GRU,与LSTM相比结构相似、参数更少。Encoder和decoder之间采取传统的attention连接机制。
在Clotho上训练结束后,我们还采用了参加2020年DCASE挑战赛时使用的强化学习方法继续训练模型。该方法基于policy gradient,用模型采样得到的整个序列的reward直接优化评价准则。我们使用self-critical sequence training,定义reward为模型采样得到的句子的CIDEr分数,baseline为模型贪婪解码得到的句子的CIDEr分数。
实验结果
表1列出了在evaluation子集上的结果,其中,SD表示SPIDEr,是比赛排名使用的指标,为自然语言生成任务中评价指标CIDER和SPICE的平均。可见,预训练encoder和强化学习大大提升了模型性能。
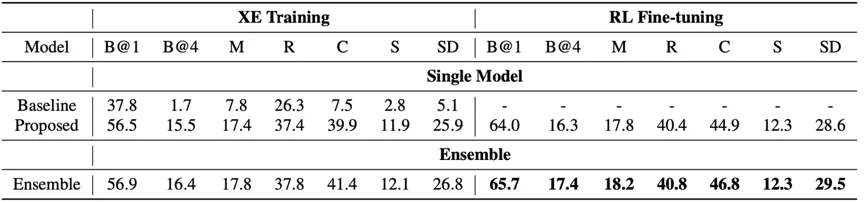
表1. 实验结果
相关工作
1. 提出Audio Caption任务并发布了第一个公开的数据集,相关成果发表于ICASSP 2019
论文:https://arxiv.org/abs/1902.09254
代码:
https://github.com/RicherMans/AudioCaption
2. 使用CRNN encoder和强化学习,在DCASE2020挑战赛中获得第四,相关成果发表于DCASE 2020 workshop
论文:
https://x-lance.sjtu.edu.cn/papers/2020/xnx98-xu-dcase2020.pdf
3. 使用在相关任务上预训练的音频encoder在音频摘要任务上做迁移学习,并探索不同数据量和模型结构对迁移学习的影响,相关成果发表于ICASSP 2021
论文:
https://ieeexplore.ieee.org/abstract/document/9413982