我系智能交互与认知工程上海高校重点实验室在机器学习、情感计算、最优化和机器翻译等领域的五篇论文,将在2016年7月9日-15日于纽约召开的第25届国际人工智能联合会大会(the 25th International Joint Conference on Artificial Intelligence, IJCAI’2016 )上发表。以下是这五篇论文的简介。
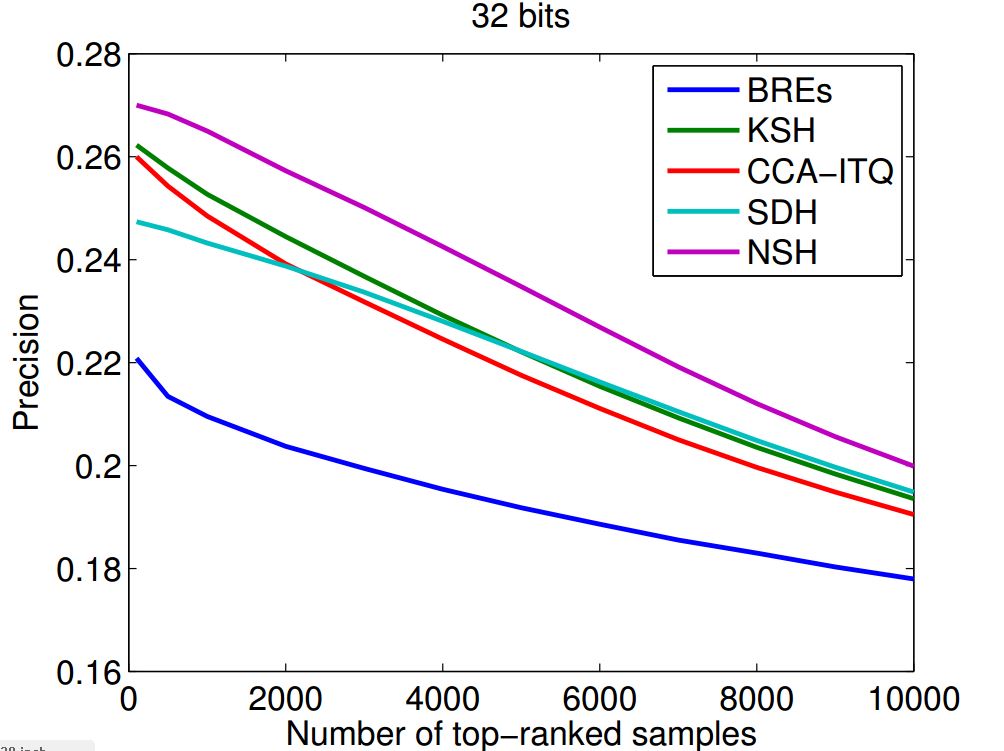
1. “Natural Supervised Hashing”
作者:刘祺,卢宏涛
简介:近十年来,随着大规模数据的出现和高维特征的使用,近似最近邻检索算法受到了学术界的重视,基于学习的哈希算法是其中一种。基于学习的哈希可以分为非监督、半监督和监督三种,本文研究监督哈希算法。监督哈希的目标在于从训练数据中学习哈希函数,使得生成的哈希码和语义相似性保持一致,即样本越相似,它们的海明距离应该越小,反之,不相似的样本海明距离应该尽量大。监督哈希的研究主要集中在目标函数的设计和与之相对的最优化算法上,本文提出一种新的非常直观的监督哈希算法,并通过实验验证其训练速度和检索性能。本文将标签向量当做理想的二位码,希望学习得到的哈希码和标签有相似的结构,即生成相近的内积。为了使得算法有更好的扩展性,我们不直接计算内积,而是使用一种保持内积的转换来隐式地达到目的,这种转换使得我们能够使用更多的训练数据,并且降低了优化难度和训练耗时。实验表明,该算法较现有算法在精度上有一定的提升。
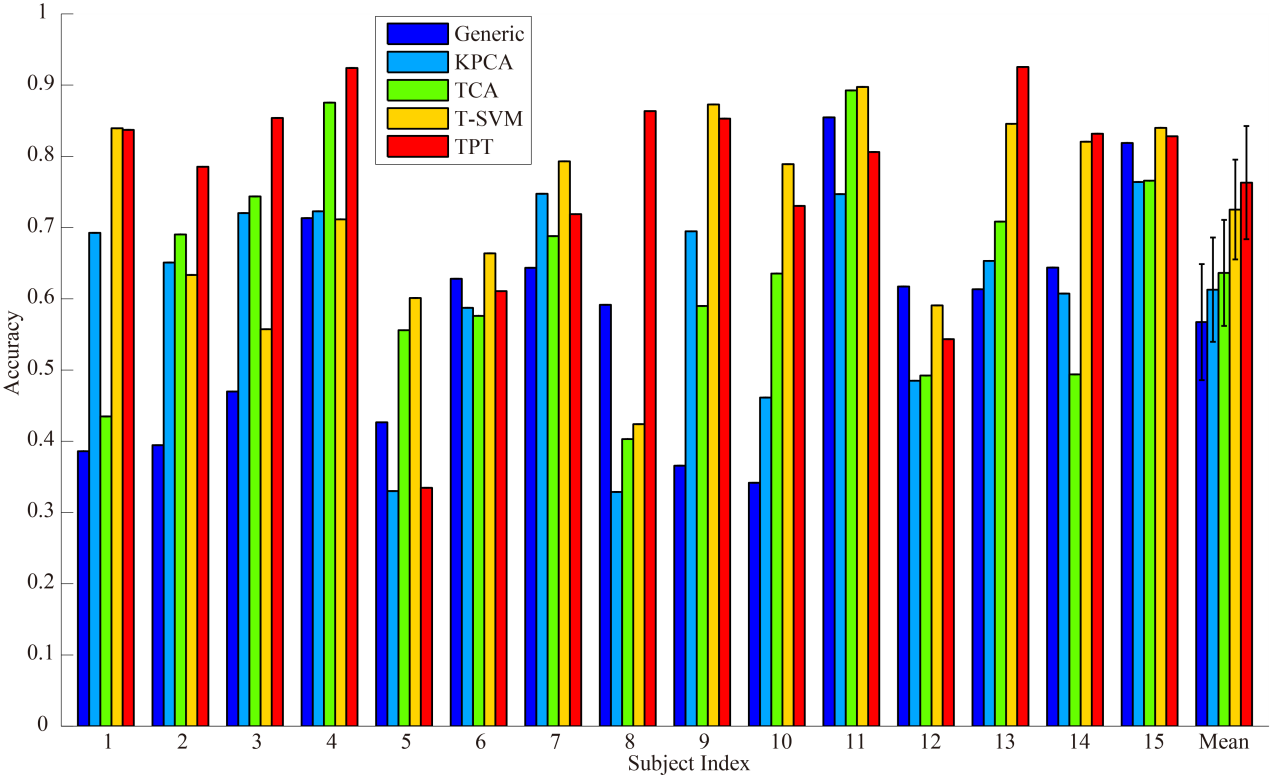
2. “Personalizing EEG-based Affective Models with Transfer Learning”
(基于迁移学习的个性化脑电情感模型研究)
作者:郑伟龙,吕宝粮
简介:在情感脑机接口中,被试间的个体差异性以及脑电信号的非平稳特性等因素影响其在实际应用中的泛化性能,降低模型精度;另一方面,采集大量具有情感标号的不同被试的脑电数据来学习特定被试的情感模型代价非常大,耗时成本高。在这篇论文中,我们提出了利用迁移学习技术,通过已有被试的标号数据,在新被试无标定数据的情况下构建其个性化脑电情感模型。我们主要探索了两类被试迁移方法:迁移成分分析(Transfer Component Analysis)以及直推式参数迁移(Transductive Parameter Transfer)。迁移成分分析方法利用特征降维方法将不同被试的特征分布投影到新的特征子空间,使得它们在新的低维子空间中差异缩小。直推式参数迁移方法对于不同被试训练单独分类器,通过回归函数学习特征分布与分类器分界面参数映射关系,再利用核函数评估新来的被试数据分布与训练数据分布关系从而预测新被试分类器参数。我们在三类情绪识别(正面、负面和中性)脑电数据集SEED(http://bcmi.sjtu.edu.cn/~seed/)中比较了它们与传统方法的性能。实验结果表明,直推式参数迁移方法相对于传统方法(56.73%),能有效提高模型精度,取得更高的平均准确率(76.31%)。
3.“Truthfulness of a Proportional Sharing Mechanism in Resource Exchange”
作者:程郁琨,邓小铁,祁琦,阎翔
简介:本文解决了资源交换问题研究中的一个开放性问题,从机制设计的角度,探讨了在资源交换博弈中任意参与者通过撒谎获益的动机和可能性,并证明了当所有博弈参与者遵循比例分配机制(proportional share mechanism)时,无法通过虚报其资源量增加其最终收益。这一结果给出了一个具有策略稳定性(strategic stability)的资源交换协议,为资源交换协议(即比例分配机制)的策略稳定性提供了新的理解方式。与此同时,本文通过网络实例验证进一步说明和确认了理论结果。结合团队成员之前的工作,我们得到了关于激励稳定性(incentive compatibility)的完整结果,即参与者有两种策略对自己的私有信息撒谎,切断与特定其它参与者的联系与谎报自己的资源总量,而他们无法通过采用其中任何一种或同时采用这两种策略,增加自己的收益。这完成了对比例分配机制的诚实性(truthfulness)的研究。
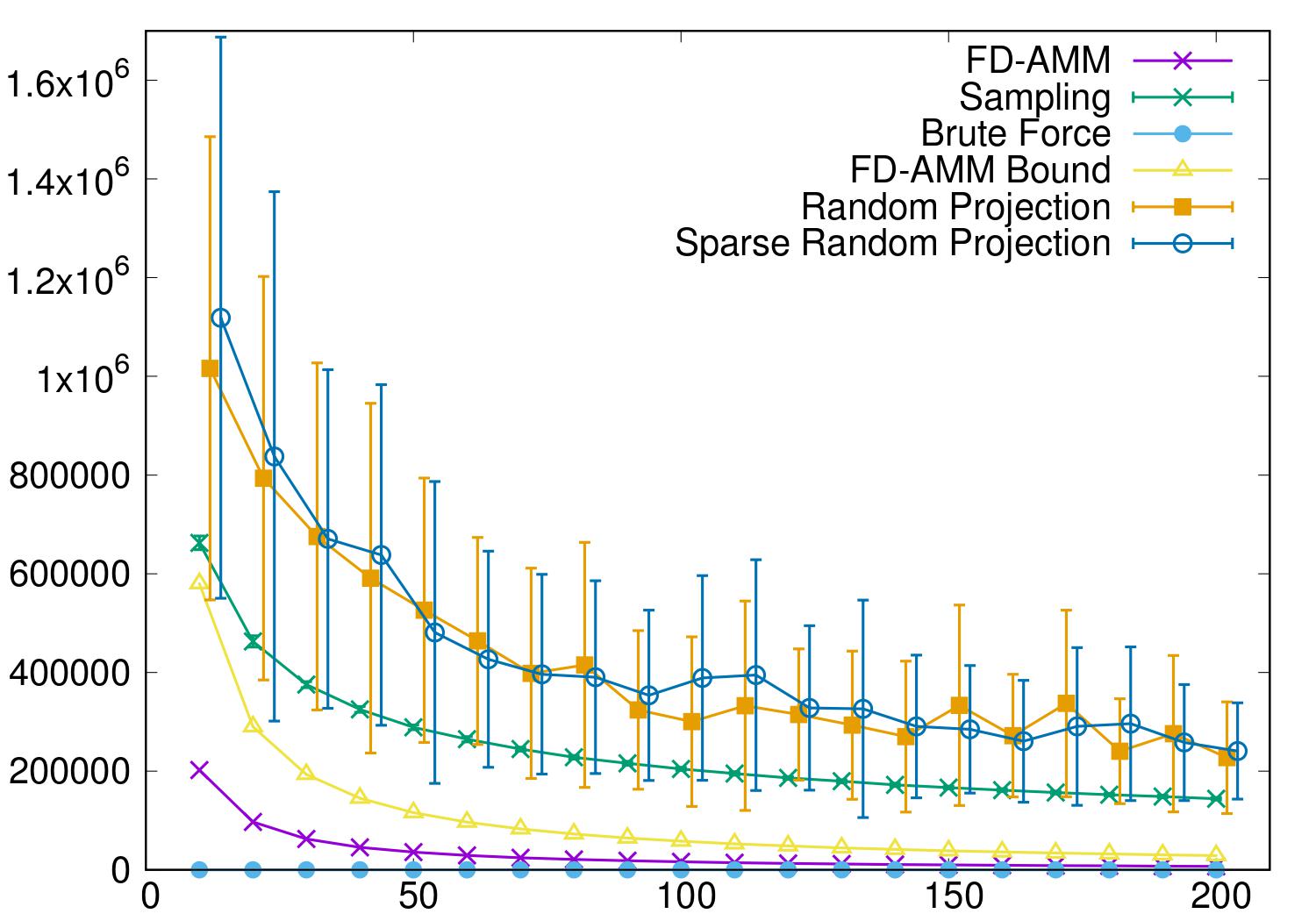
4. “Frequent Direction Algorithms for Approximate Matrix Multiplication with Applications in CCA”
作者:叶巧敏,张志华
简介:随着互联网信息规模的急速膨胀,近似矩阵乘法也变得越加重要,因为它使得矩阵运算面对大规模数据时仍然可行。现有大部分近似矩阵乘法的工作都是基于随机选择或者随即投影。在该论文中,我们提出了一种新的确定性算法(FD-AMM)来近似计算两个矩阵的乘积。此外,该算法可以在流模式下运行。我们的算法是基于最近提出的矩阵概率草图计算方法Frequent Directions(FD)。在相同的空间复杂度之下,我们的算法比随机选择和随机投影具有更高的准确度。此外,我们的算法还可以用来计算流模式下两个矩阵的典型相关分析(CCA),比传统的计算方法节省更多的空间。实验结果证明了我们的算法的有效性。
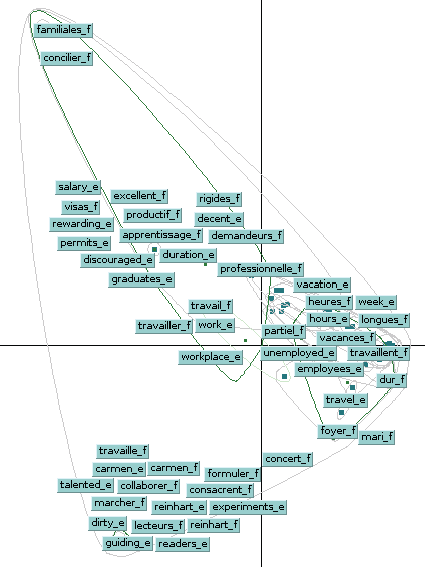
5. “A Bilingual Graph-based Semantic Model for Statistical Machine Translation”
(基于双语图语义模型的机器翻译)
作者:王瑞,赵海,Sabine Ploux,吕宝粮,Masao Utiyama
简介:传统的双语词向量表示在一系列工作中展示出可以提升机器翻译的表现,但是已有的工作存在一些缺点:1)其大多只是简单利用上下文或者滑动窗口的词信息来构建词之间的关系;2)将词作为语义单元的最小单位,而并非更为准确的语义信息本身。为了克服这些缺点,我们提出了一个新的双语语义单元--双语上下文词团(Bilingual Contexonym Cliques, BCC)。区别于目前已有的直接利用上下文或者滑动窗口的词空间表示方法,BCC蕴含更多的语义信息,能够更加准确地反映词之间的关系。基于BCC,我们构建了双语图语义模型,利用对应分析技术将词表示成低维度的向量。实验结果表明,双语图语义模型可以显著地提高机器翻译的表现,并且在准确度和速度上都超过了传统的双语词向量表示方法。
本工作的法国合作方为法国国家科学研究院(Centre National de la Recherche Scientifique, CNRS)的Sabine Ploux教授。CNRS是法国同时也是欧洲最大的基础研究机构,拥有16位诺贝尔奖与9位菲尔兹奖获得者,具有着悠久卓越的传统。日本合作方为日本国立情报通讯机构(National Institute of Information and Communications Technology, NICT)的Masao Utiyama高级研究员。NICT是日本重要的信息技术领域的研究和开发机构,同时是日本国家时间标准等一系列国际标准的制定机构。
第25届国际人工智能联合会大会共收到2294篇论文投稿,录用率低于25%。另外,在IJCAI’15上,我系智能交互与认知工程上海高校重点实验室共发表了三篇论文,论文作者分别是吕宝粮教授、张丽清教授、张志华教授、他们的学生及合作者。